
검색엔진 서버
아파치 솔라, 루씬, 넛치

아파치 솔라Solr는 검색 서버, 루씬Lucene은 검색을 위한 라이브러리, 넛치Nutch는 자료와 정보를 수집하는 크롤러 역할

아파치 루씬, Lucene
검색 엔진의 색인과 검색을 위한 자바 라이브러리
1) 특징
- 확장 가능한 고성능 정보검색 라이브러리
- 아파치 재단에서 만들어진 프로젝트로 다양한 플랫폼을 지원
- 색인러Indexer와 검색러Searcher로 구성
- 독립된 프로그램이 아닌 단순한 소프트웨어 라이브러리
- 프로그램에 텍스트 색인과 검색 기능을 추가할 수 있도록 지원
- 검색에 대한 전문적인 지식을 필요로 하지 않으며 기본 클래스들을 사용하여 색인과 검색 기능을 직접 추가할 수 있음
2) 기능
- 색인을 저장할 수 있는 곳
→ RAMDirectory : 컴퓨터의 메인 메모리를 색인 장소로 사용
→ FSDirectory : 디스크의 파일 시스템에 색인을 저장
→ JDBCDirectory : DB를 색인 저장소로 사용하는 방법
- 색인 기능 지원
- 검색 기능 지원
- 다양한 나라의 Full Text 분석기 지원
3) 적용 사례
- 내용 검색 : 저장된 문서에서 특정 내용을 검색할 수 있는 애플리케이션
- 뉴스 서비스 : 뉴스가 도착했을 때 기사를 색인할 수 있는 뉴스 서버
- 이메일 검색 : 저장된 메시지를 검색하고 새 메시지를 색인에 추가할 수 있는 이메일
- 버전 및 콘텐츠 관리 : 문서(버전)을 색인화해서 쉽게 검색할 수 있는 문서 관리 시스템
- 웹 페이지 검색 : 사용자가 방문한 모든 웹 페이지를 색인화하기 위해 개인 검색 엔진을 만들 수 있는 웹 브라우저 또는 프록시 서버
- 온라인 문서 검색 : 온라인 문서 또는 저장된 출판물을 검색할 수 있는 CD기반이나 웹 기반 또는 어플리케이션에 포함된 문서 판독기
4) 장점
- 복잡한 검색 표현식 제공
- 라이브러리이기 때문에 유연성 높음
- 여러 데이터소스를 합쳐 통합 검색 가능
- 검색 결과 하이라이트 제공
- 속도 향상을 위해 메모리에 색인 데이터를 올려 사용 가능

아파치 넛치, Nutch
오픈소스 웹 검색 소프트웨어로 웹 크롤러의 기능을 제공
1) 특징
- 광고로 뒤덮인 인터넷 검색 사이트에서 상업적인 요소를 배제하고 검색 그 자체로의 검색을 구성하고자 진행된 루씬 기반의 오픈 소스 인터넷 웹 검색엔진 프로젝트
- 루씬을 통하여 검색할 수 있도록 정보들을 수집
- 여러 가지 플러그인을 추가할 수 있도록 모듈화가 잘 되어있음
- 자바로 구현되어 있지만 데이터는 특정 언어와 관계없는 형식으로 저장
- 100만 페이지 정도를 검색 가능
- 여러 대의 머신에서 수행될 수 있도록 맵리듀스Mapreduce와 분산파일처리를 구현(요즘은 하둡 프로젝트를 통하여 따로 관리)
2) 구조
· Crawler, 크롤러
- 웹 데이터 들을 효과적으로 가져올 수 있는 fetcher들을 가지고 목표로 하는 URL들의 데이터를 수집
· Repository, 레파지토리
- 수집된 웹 데이터들을 저장
- Web DB와 Segment
· Indexer, 인덱서
- 수집된 데이터를 루씬에서 사용 가능한 Index 형식으로 구성
· Searcher, 서치어
- 루씬에서 Searcher에서 사용
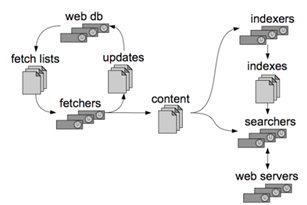
3) 검색 방법
① 웹 서버가 사용자의 검색 요청을 받는다.
② 쿼리 핸들러가 검색어를 가공해서 다수의 색인 검색 서버로 전달한다.
③ 쿼리 핸들러가 넘긴 검색어에 대해 여러 개의 색인 서버에서 결과가 나오는데 이 결과를 가장 점수가 높은 순서로 정렬한다.
④ 만약 1~2초가 지난 후에 결과를 알려주지 않는 서버가 있다면 결과에 포함하지 않고 무시한다.
* 사용자가 느끼기에 2초 안에 결과가 나오도록 보장

아파치 솔라, Solr
오픈 소스 엔터프라이즈 검색 서버
1) 특징
- 파일을 인덱스하는 검색엔진
- XML요청을 HTTP를 통해 보내는 웹 서비스 API가 있는 검색 서버
- 솔라 검색서버 URL을 사용하여 인터넷을 통해 파일을 질의, 인덱스 하는 어느 곳에서나 접근가능
- 다른 솔라 검색 서버로 캐싱과 복사가 가능한 최적화된 검색 서버
- 루씬 검색 라이브러리를 사용하며 확장
- 크게색인과 검색 두 가지 기능을 제공
2) 기능
① 색인 : HTTP 프로토콜 상에서 XML을 통해서 색인
② 검색 : HTTP GET으로 쿼리를 보낼 수 있으며, XML의 형태로 결과 값을 얻음
* 그 외 특징
· Schema, 스키마
- 색인할 문서의 필드와 그 필드 타입을 따로 정의
- Lucene 형태소 분석기 정의 가능
- 외부 파일을 통해 금지어 등을 설정가능
· Caching, 캐싱
- 쿼리 결과, 필터, 문서 캐쉬 인스턴스를 설정 가능
- 캐시Cache 수행 유연
· Replication, 리플리케이션 복제
- rsync transport를 통해 효과적인 색인의 부분 분산이 가능
· Admin Interface
- 캐시Cache의 이용, 업데이트update, 쿼리query 상태를 알림
- 형태소 분석 디버거를 제공
- 웹 쿼리 인터페이스를 제공하며 검색 결과의 설명을 제공

'컴퓨터공학과 > 그외' 카테고리의 다른 글
| UNICODE 특장점, 유니코드 변환 방식(UTF-8과 UTF-16 특장점, 비교, 표현방법) / 한글 유니코드 (0) | 2020.04.27 |
|---|---|
| [WEKA] java에서 weka 사용하기 / 분류·클러스터 구현 템플릿 및 예제 (0) | 2020.04.26 |
| IEEE Citation Reference. 참고문헌 표기법. (0) | 2020.03.15 |
| [Refactoring] 6. 타입 코드 (1) | 2015.11.18 |
| [Refactoring] 5. 널 객체 (0) | 2015.11.18 |