| UNICODE, 유니코드 |

정의
컴퓨터에서 세계 각국의 언어를 통일된 방법으로 표현할 수 있게 제안된 국제적인 문자 코드 규약
등장배경
- 여러 나라 언어들을 출력하는 각기 다른 표현법이 많음(ASCII, Codepage, CP437, Cp860, CP932, CP949 등)
- 여러 나라 언어들을 표현할 수 있는 크기의 구조를 가진 문자 코드가 없었음. 즉, 기존의 인코딩들은 그 규모나 범위 면에서 한정되어 있었음
- 다국어 환경에서는 서로 호환되지 않는 문제점을 가짐
목적
- 이 세상의 모든 글자를 담자!
- 현존하는 문자 인코딩 방법들을 모두 유니코드로 교체하는 것
특징
- 유니코드 협회(Unicode Consortium)에서 제정함
- 표준에는 ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자들을 다루기 위한 알고리즘 등을 포함하고 있음
- 유니코드가 다양한 문자 집합들을 통합하는 데 성공하면서 유니코드는 컴퓨터 소프트웨어의 국제화와 지역화에 널리 사용되게 되었으며 비교적 최근의 기술인 XML, 자바, 그리고 최신 운영 체제 등에서도 지원하고 있음
- 한국어 발음을 나타날 때는 예일 로마자 표기법의 변형인 ISO/TR11941을 사용함
- UCS2와 UCS4 두가지 종류로 나뉨
· UCS2 : 일반적으로 사용하는 언어들을 포함하는 셋. 모두 2byte로 표현 됨
· UCS4 : 산스크리트어, 고대 이집트어 등을 포함
다국어 기본 평면, BMP(Basic Multilingual Plane)

- ISO 10646에서 정의
- 유니코드가 표현하는 언어들에 대한 구성도
- 유니코드의 첫번(0) 평문으로, 0x0000부터 0xFFFF까지 표기됨
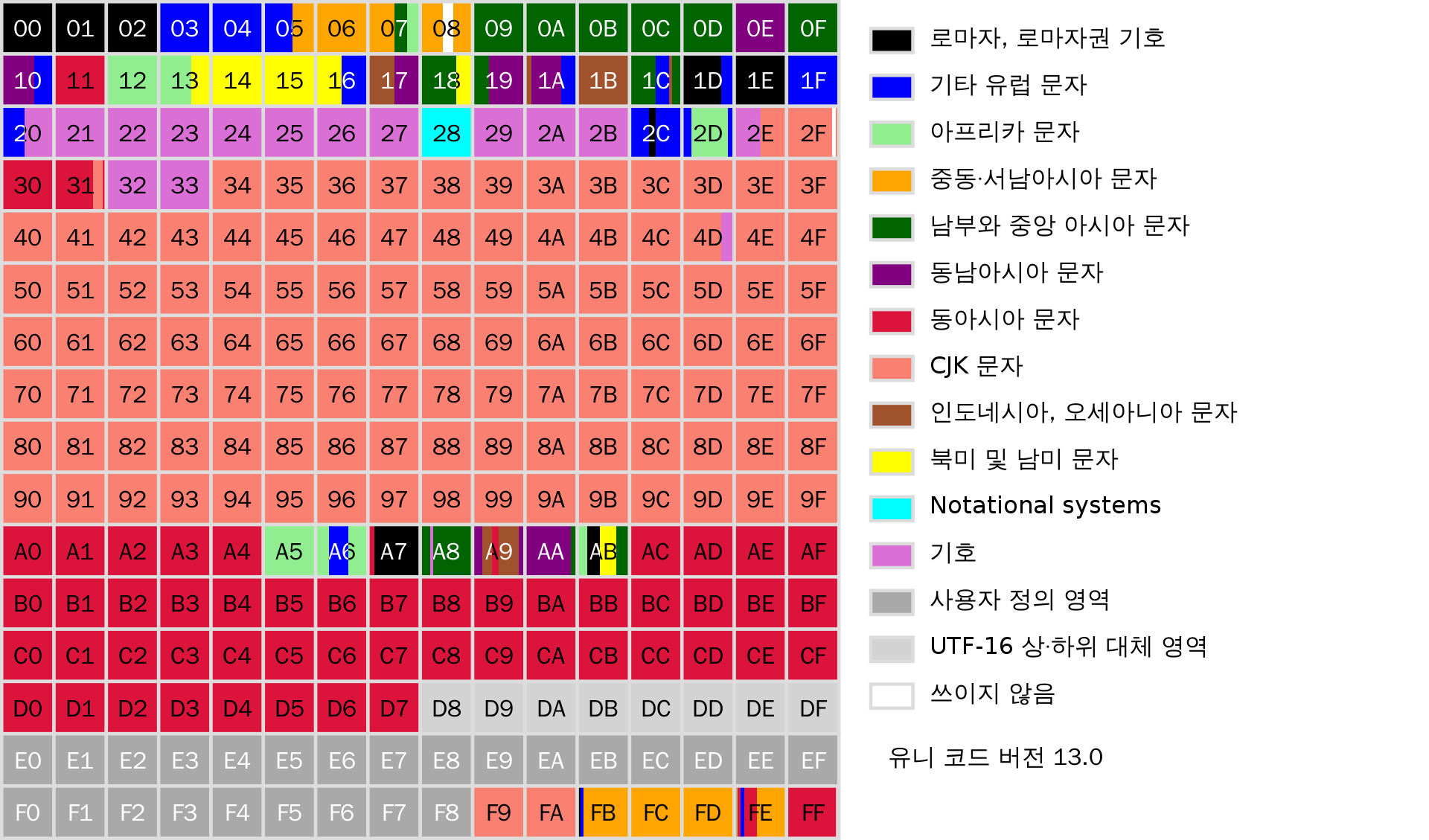
- BMP에는 거의 모든 근대 문자와 특수 문자가 포함되어 있으며, 그중 대부분은 한글, 한중일 통합한자들로 이루어져 있음
- 각 언어들이 어느 영역에 있는지 표시함(한글의 경우 AC근처부터 D7까지 표현됨)

- BMP에서 ‘각’이라는 글자는 U+AC01에 대응됨
- ‘각’을 UTF-16로 표현하면 0xAC01
인코딩 방법
- UTF-8 : 1~3byte를 사용하여 BMP를 모두 표현 가능
- UTF-16 : 2byte를 사용하여 BMP를 모두 표현 가능
- UTF-32 : 4byte를 사용하여 BMP와 그 외 영역까지 표현 가능
| UTF-8, Unicode Transformation Format-8 |
네이버 통합검색에서 ‘?’ , ‘□’ 사라진다…UTF-8 인코딩 적용
2011.07.07 18:10:44 / 이민형 기자 kiku@ddaily.co.kr
[디지털데일리 이민형기자] 앞으로 네이버 통합검색에서 ‘?’, ‘□’로 표시되는 글자가 사라질 전망이다. 네이버 통합검색 인코딩 방식이 UTF-8로 변경됐기 때문이다.
....중략
이전까지 네이버는 ‘EUC-KR’ 인코딩 방식을 사용해왔다. EUC-KR 방식은 흔히 말하는 완성형 코드로 현대 한글 1만1172자 중 2350자만 표현 가능하기 때문에, 나머지 8822자에 속한 글자를 표시하지 못하는 문제가 있었다. 반면 UTF-8 인코딩은 1만1172자의 현대 한글 뿐 아니라 한글 고어, 일본어, 중국어 등 모든 언어의 문자를 처리할 수 있다는 장점을 갖는다. 이러한 이유로 지난해부터 정부 공공 정부시스템에서도 UTF-8 인코딩을 적극적으로 도입하고 있다.

네이버 관계자는 “네이버는 UTF-8 문자 인코딩이 가지는 이러한 장점들을 고려하고 국제적인 표준화 추세에 발맞춰, 네이버 통합검색에 UTF-8 인코딩을 적용하는 개선을 진행해 왔다”라며 “지난 4월 통합검색 출력 인코딩이 UTF-8로 전환됐고, 7일부로 입력 인코딩도 UTF-8로 개선했다”고 전했다.
* 네이버 통합검색은 EUC-KR 인코딩 방식을 사용했을 때 깨졌던 문자들을 현대 한글뿐만 아니라 한글 고어, 일본어, 중국어 등 모든 언어의 문자를 처리할 수 있는 UTF-8 인코딩 방식을 도입하여 깨짐을 방지함
특징
- 유니코드 변환 형식, 유니코드를 위한 가변길이 문자 인코딩 방식중 하나
- UTF-8 인코딩은 유니코드 한 문자를 나타내기 위해 1바이트에서 4바이트까지를 사용
→ U+0000부터 U+007F 범위에 있는 ASCII 문자들은 UTF-8에서 1바이트만으로 표시함
- 유니코드 코드 포인트를 나타내는 비트들은 여러 부분으로 나누어 UTF-8로 표현된 바이트의 하위 비트들에 들어 감
- 유니코드가 나오기 이전에 ASCII 인코딩으로 표기하였는데 이는 1바이트로 표현되어 ASCII로 표현된 문자를 UTF-16으로 디코딩하려고하면 해석에 오류가 생길 것이 뻔하여 이에 따라 UTF-8을 사용하게 되었고, UTF-8 중 한 바이트로 구성된 인코딩 규칙의 경우 ASCII와 동일하게 사용됨
- U+007F까지의 문자는 7비트 ASCII 문자와 동일한 방법으로 표시되며, 그 이후의 문자는 다음과 같은 4바이트까지의 비트 패턴으로 표시됨
- 7비트 ASCII 문자와 혼동되지 않게 하기 위하여 모든 바이트들의 최상위 비트는 1임
설계 원칙
- 1바이트로 표시된 문자의 최상위 비트는 항상 0임
- 2바이트 이상으로 표시된 문자의 경우, 첫 바이트의 상위 비트들이 그 문자를 표시하는 데 필요한 바이트 수를 결정
→ 1바이트는 0으로, 2바이트는 110으로 시작하고, 3바이트는 1110으로 시작함
- 첫 바이트가 아닌 나머지 바이트들은 상위 2비트가 항상 10임
장점
- ASCII 인코딩은 UTF-8의 부분 집합으로 일반적인 ASCII 문자열은 올바른 UTF-8 문자열이며 따라서 하위 호환성이 보장됨
- UTF-8 문자열은 바이트 단위로 정렬을 수행하는 알고리즘으로도 코드 포인트 단위로 올바르게 정렬 가능
- UTF-8과 UTF-16은 XML 문서의 표준 인코딩으로, 다른 인코딩들을 사용하려면 외부에서 또는 문서 안에서 명시적으로 인코딩을 정해야 함
- 다른 인코딩과의 왕복 변환이 간단
- 바이트 단위 문자열 검색 알고리즘들을 그대로 사용할 수 있음
- 간단한 알고리즘을 통하여 UTF-8 문자열임을 확인할 수 있음. 즉, 다른 인코딩에서 나타나는 바이트들이 올바른 UTF-8 문자열일 가능성은 낮음
- U+0000을 표현할 때를 제외하면, 널 문자는 UTF-8 문자열 안에 나타나지 않음. 따라서 널 문자로 끝나는 문자열을 사용하는 C 언어의 문자열 함수(strncpy() 같은)를 그대로 사용할 수 있음
단점
- 나쁘게 만들어진(그리고 현재 표준을 따르지 않는) UTF-8 파서는 서로 다른 가짜 UTF-8 표현(예를 들어서 너무 긴 형식)을 같은 유니코드 문자열로 해석할 수 있음
- 대부분의 UTF-8 문자열은 일반적으로 적당한 기존 인코딩으로 표현한 문자열보다 더 큼
→ 판독 기호를 사용하는 대부분의 라틴 알파벳 문자는 적어도 2바이트를 사용, 한중일 문자들과 표의 문자들은 적어도 3바이트를 사용함
- 한중일 문자들과 표의 문자를 제외한 거의 모든 기존 인코딩들은 한 문자에 1바이트를 사용하므로 문자열 처리가 간편한 반면 UTF-8은 그렇지 않음
| UTF-16, Unicode Transformation Format-16 |
특징
- 유니코드 변환 형식, 유니코드를 위한 가변길이 문자 인코딩 방식중 하나
- UTF-16은 유니코드 컨소시엄과 ISO/IEC 10646에 의해 정의되어 있음
- 기본 다국어 평면은 U+0000 에서 U+FFFF에 놓인 문자를 담고 있으며 이 영역에는 우리가 쉽게 생각할 수 있는 문자들이 포함되며, 한글, 한자 등은 모두 여기에 포함되어 있음
- 기본 다국어 평면의 문자들은 곧바로 16비트 값으로 대응되어 인코딩됨
→ 유니코드에서 지원하는 BMP를 그대로 일대일 매핑하여 사용되는 인코딩으로 2바이트로 표현됨
장점
- 가변 길이 인코딩이며 다른 문자는 다른 바이트 수로 표현될 수 있는 UTF-8에 비해 고정 길이 인코딩이 가능함
- BMP에 들어 있는 한중일 문자들은 UTF-8에서 3바이트로 표현되지만, UTF-16에서는 2바이트로 표현됨.
→ 따라서 UTF-16에서는 이러한 문자를 표현하기 위하여 더 적은 바이트가 필요하며 UTF-8과 비교할 때 최대 50%까지 크기가 줄 수 있음
단점
- UTF-8은 바이트 순서가 정해져 있기 때문에 바이트 순서 문자(BOM, U+FEFF)이 필요하지 않지만 UTF-16은 바이트 순서를 나타내기 위하여 BOM이 필요함
- 유닉스의 파일 시스템과 여러 도구들은 옥텟을 기본 단위로 하며, 널 문자와 경로 식별자(/, 0x2F)에 특별한 의미를 부여하는 경우가 많은데, UTF-8은 ASCII와 호환되기 때문에 0x00이나 0x2f 옥텟이 항상 U+0000과 U+002F에 대응되므로 기존 API를 약간 수정해서 쓸 수 있으나, 0x00이나 0x2f 옥텟이 U+0000과 U+002F가 아닌 다른 문자에서도 나타날 수 있는 UTF-16은 불가능함
- U+0000부터 U+007F까지의 공백과 문장 부호를 포함한 ASCII 문자들은 1바이트로 표현할 수 있기 때문에 한중일 문자와 표의 문자를 사용하지 않는 대부분의 문자열을 UTF-8보다 더 작은 크기로 표현할 수 없음
| UTF-8 VS UTF-16 |
표기법
|
코드범위 |
UTF-16 |
UTF-8 |
설명 |
|
000000~00007F |
0xxxxxxxx |
0xxxxxxx |
ASCII와 동일한 범위 |
|
000080~0007FF |
00000xxx xxxxxxxx |
110xxxxx 10xxxxxx |
첫바이트 110 또는 1110로 시작 바이트들은 10으로 시작 |
|
000800~00FFFF |
xxxxxxxx xxxxxxxx |
1110xxxx 10xxxxxx 10xxxxxx |
첫바이트 110 또는 1110로 시작 바이트들은 10으로 시작 |
|
010000~10FFFF |
110110yy yyxxxxxx |
11110zzz 10zzxxxx |
UTF-16 서로게이트 쌍 영역 (yyyy = zzzzz - 1). UTF-8로 표시된 비트 패턴은 실제 코드 포인트와 동일 |
표기 예제
'삼' 표기법

삼 = U+C0B0C
|
코드범위 |
UTF-16 |
UTF-8 |
설명 |
|
000800~00FFFF |
xxxxxxxx xxxxxxxx |
1110xxxx 10xxxxxx 10xxxxxx |
첫바이트 110 또는 1110로 시작 바이트들은 10으로 시작 |
- UTF-16 : 0xC0B0C
- UTF-8 : 0xC0BC
= 11000000 10111100
= 11101100 10000010 10111100
= EB 82 BC
'컴퓨터공학과 > 그외' 카테고리의 다른 글
| [기계학습] Machine Learning in Action - 1장. 기계학습 기초(기계학습이란/주요 용어/알고리즘 선정방법/머신러닝개발단계) 요약정리 (4) | 2020.05.04 |
|---|---|
| 네이티브 앱 vs.웹 앱 - 사용자 경험(UX)에 비추어 본 모바일 앱의 발전 방향 (0) | 2020.04.30 |
| [WEKA] java에서 weka 사용하기 / 분류·클러스터 구현 템플릿 및 예제 (0) | 2020.04.26 |
| 검색엔진 서버 - 아파치 솔라·루씬·넛치 알아보기(인덱서, 서처, 크롤러 특장점/기능/검색방법) (0) | 2020.04.22 |
| IEEE Citation Reference. 참고문헌 표기법. (0) | 2020.03.15 |